I was very excited to create my first > petabyte (pebibyte actually) single filesystem this afternoon! And sure enough, df -h reported the size in PiB. I remember filing a bug on df not supporting terabytes (tebibytes) over a decade ago. Thus, I was slightly surprised to discover that it knows about PiBs.
$ df -h /dev/mss1 /dev/dl1 Filesystem Size Used Avail Use% Mounted on /dev/mss1 1.1P 663T 386T 64% /net/mss1 /dev/dl1 350T 18M 350T 1% /net/dl1
$ rpm -q coreutils coreutils-8.4-31.el6_5.1.x86_64
This made me curious as to how ridiculously large of units df, dd, etc. support. It turns out that coreutils is using a function from gnulib to do the “humanizing”.
From gnulib/lib/human.h:
char *human_readable (uintmax_t, char *, int, uintmax_t, uintmax_t);
From gnulib/lib/human.c:
static const char power_letter[] =
{
0, /* not used */
'K', /* kibi ('k' for kilo is a special case) */
'M', /* mega or mebi */
'G', /* giga or gibi */
'T', /* tera or tebi */
'P', /* peta or pebi */
'E', /* exa or exbi */
'Z', /* zetta or 2**70 */
'Y' /* yotta or 2**80 */
};
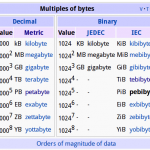
Holy smokes! It supports the entire range of defined SI prefixes. df is ready to support “yotta-scale” filesystems; that’s a billion PiBs. I think that will hold me over for awhile. 😉 It makes me wonder if we’ll see new SI prefixes defined in my lifetime driven by storage capacities…